Machine Learning - Part 1 - Introduction
Following is my notes from the book Python Machine Learning with PyTorch and Scikit-Learn by Sebastuan Raschka, et. al.
Setup Python Development Environment
1
2
3
conda create -n "pyml-book" python=3.9 numpy=1.21.2 scipy=1.7.0 scikit-learn=1.0 matplotlib=3.4.3 pandas=1.3.2
conda activate pyml-book
Go for either miniforge or miniconda distributions and set it up as described above.
Types of Machine learning
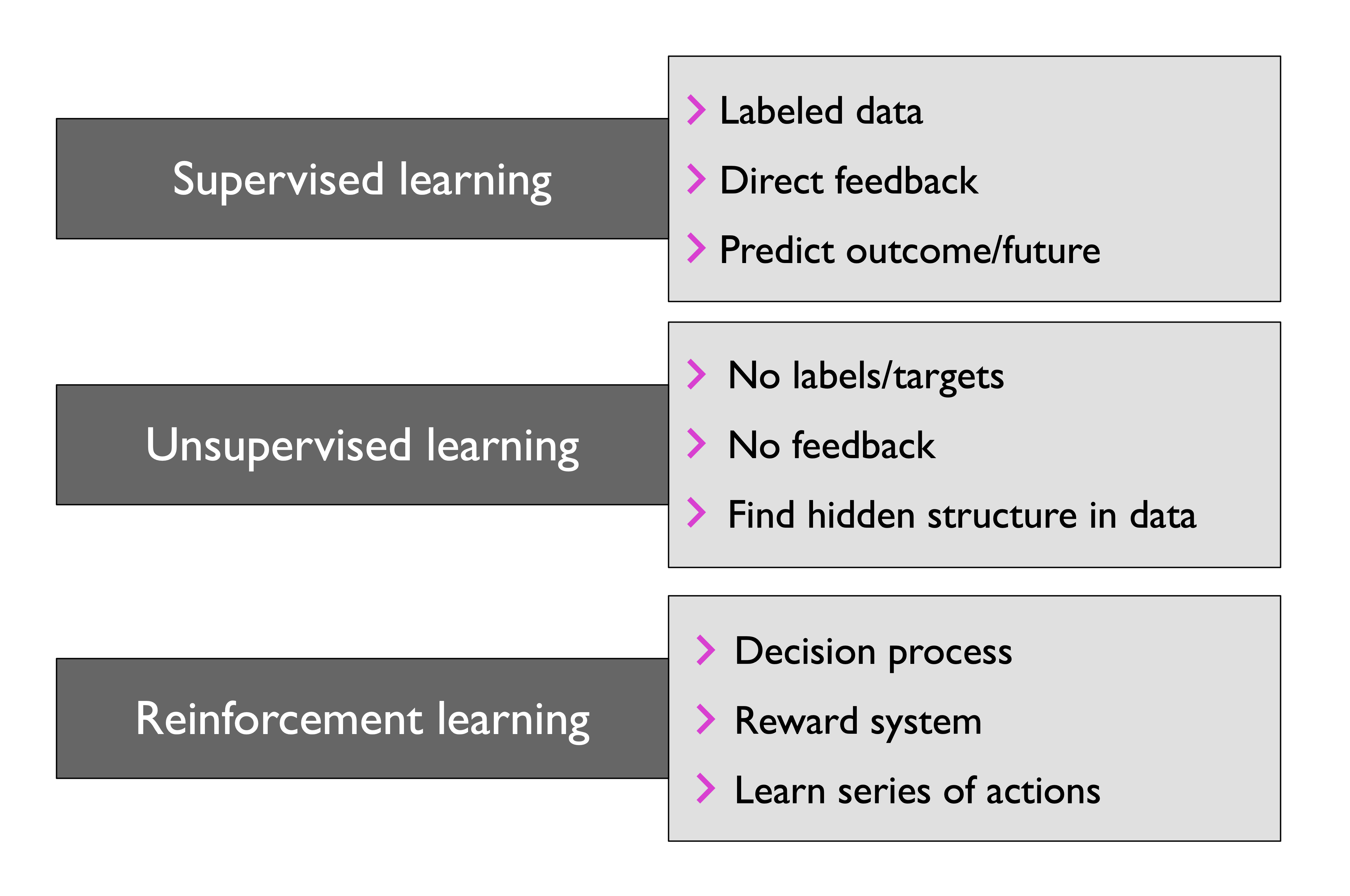
Supervised Learning
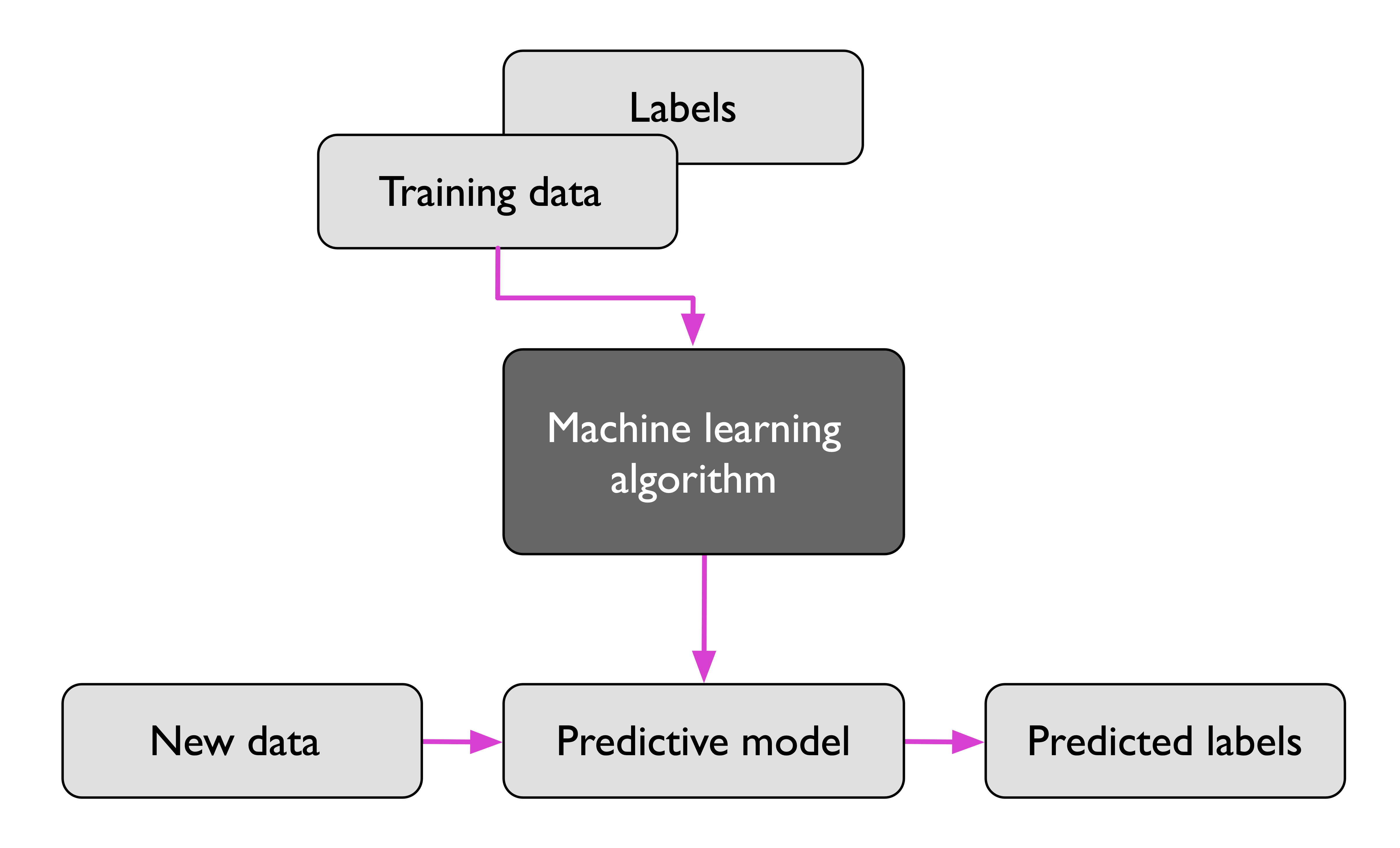
A supervised learning task with discrete class labels, such as in the previous email spam filtering example, is also called a classification task. Another subcategory of supervised learning is regression, where the outcome signal is a continuous value.
In regression analysis, we are given a number of predictor (explanatory) variables and a continuous response variable (outcome), and we try to find a relationship between those variables that allows us to predict an outcome.
- the predictor variables are commonly called “features,”
- and the response variables are usually referred to as “target variables.”
Reinforcement Learning
In reinforcement learning, the goal is to develop a system (agent) that improves its performance based on interactions with the environment.
Unsupervised Learning
Clustering is an exploratory data analysis or pattern discovery technique that allows us to organize a pile of information into meaningful subgroups (clusters) without having any prior knowledge of their group memberships.
Unsupervised dimensionality reduction is a commonly used approach in feature preprocessing to remove noise from data, which can degrade the predictive performance of certain algorithms. Dimensionality reduction compresses the data onto a smaller dimensional subspace while retaining most of the relevant information.